Базовые идеи и интуиция
причинно-следственного анализа данных
«Correlation does not even imply correlation. That is, correlation in the data you happen to have does not necessarily imply correlation in the population of interest. Andrew Gelman»
Блок 1 Мотивационные примеры


Два вопроса за одной мантрой
«Корреляция не подразумевает причинность» — все слышали.
Но за этой фразой скрываются два разных вопроса:
-
Что подразумевает причинность? Какие условия нужны, чтобы из данных делать причинные выводы?
-
Что всё же подразумевает корреляция? Правда ли, что статистическая ассоциация «ничего не значит»?
На оба вопроса мы ответим — и ответы окажутся неожиданными.

Turn into data

Структура важна не меньше полноты данных
Данные: коты $C$, гравитация $G$, удобное место $F$
| # | C | F | G |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 0 |
| 5 | 1 | 1 | 0 |
| 6 | 1 | 1 | 0 |
| 7 | 0 | 1 | 1 |
| 8 | 0 | 1 | 0 |
| # | C | F | G |
|---|---|---|---|
| 9 | 1 | 0 | 0 |
| 10 | 1 | 0 | 0 |
| 11 | 1 | 0 | 0 |
| 12 | 0 | 0 | 0 |
| 13 | 0 | 0 | 0 |
| 14 | 0 | 0 | 0 |
| 15 | 1 | 0 | 1 |
| 16 | 0 | 0 | 1 |
| Cat | Not Cat | |
|---|---|---|
| Fit | 3/6 (50%) | 1/2 (50%) |
| Not | 1/4 (25%) | 1/4 (25%) |
| Total | 4/10 (40%) | 2/6 (33%) |
Без $F$: $C$ и $G$ коррелируют.
С $F$: корреляция исчезает.
$G \rightarrow F \rightarrow C$
Блок 2 — Как мы ошибаемся
когнитивные искажения
CogBias: To see an illusion as illusion is not yet to escape it

CogBias: Mapping abstraction to pattern

CogBias: Thatcher effect

CogBias: Hypothesis confirmation

CogBias: Expectations

CogBias:Expectaitions matter

CogBias:Expectaitions matter
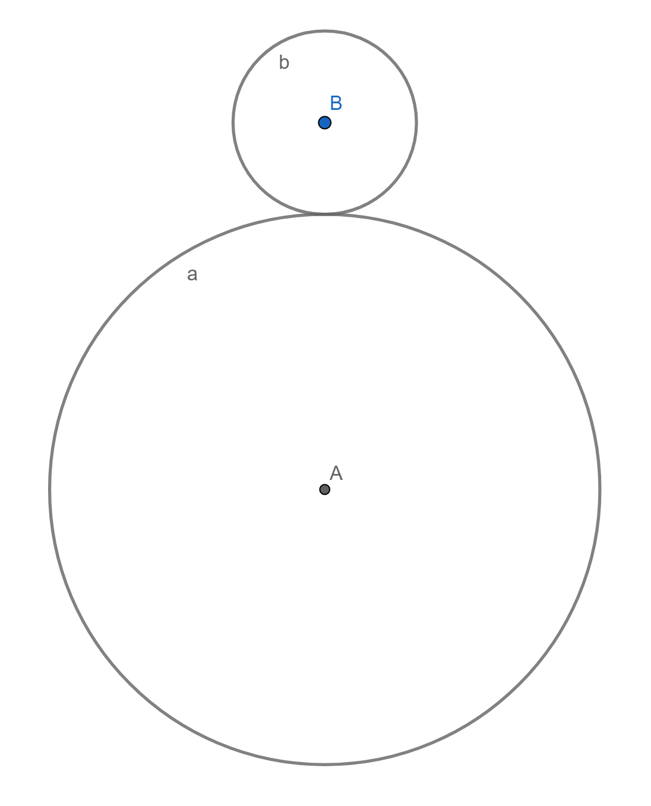
КИ с числами: парадокс вращения монеты
Радиус окружности a в три раза больше радиуса b.
Окружность b катится вокруг a без проскальзывания.
Сколько оборотов совершит b?
| a) 3/2 | b) 3 |
| c) 6 | d) 9/2 |
| e) 9 |
КИ с числами: интуиция говорит «3»
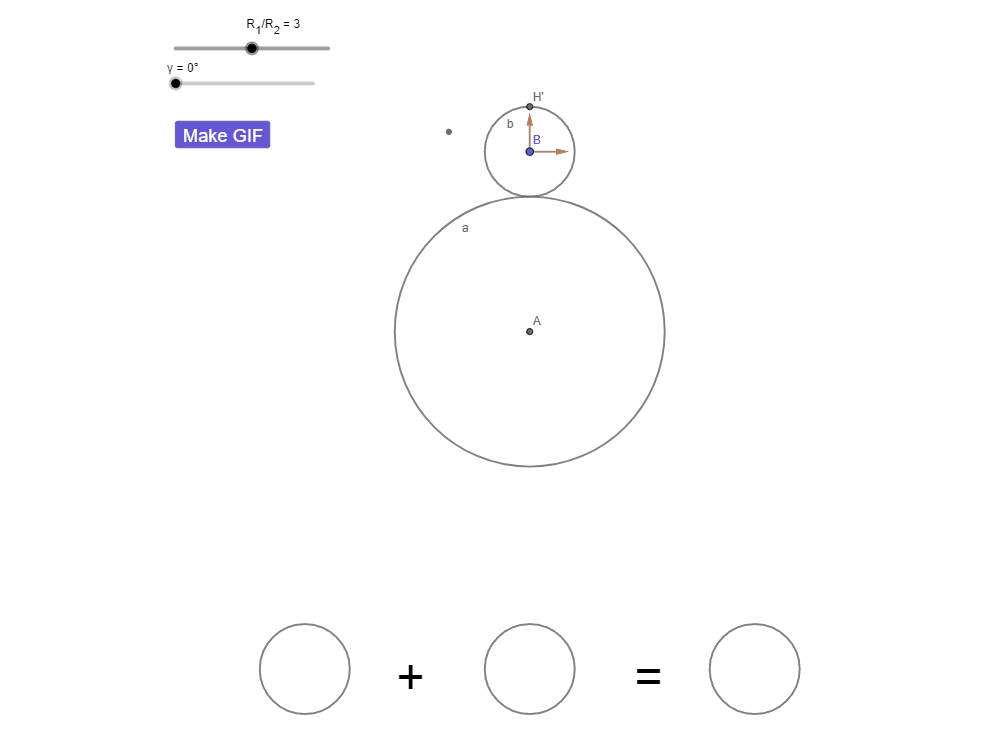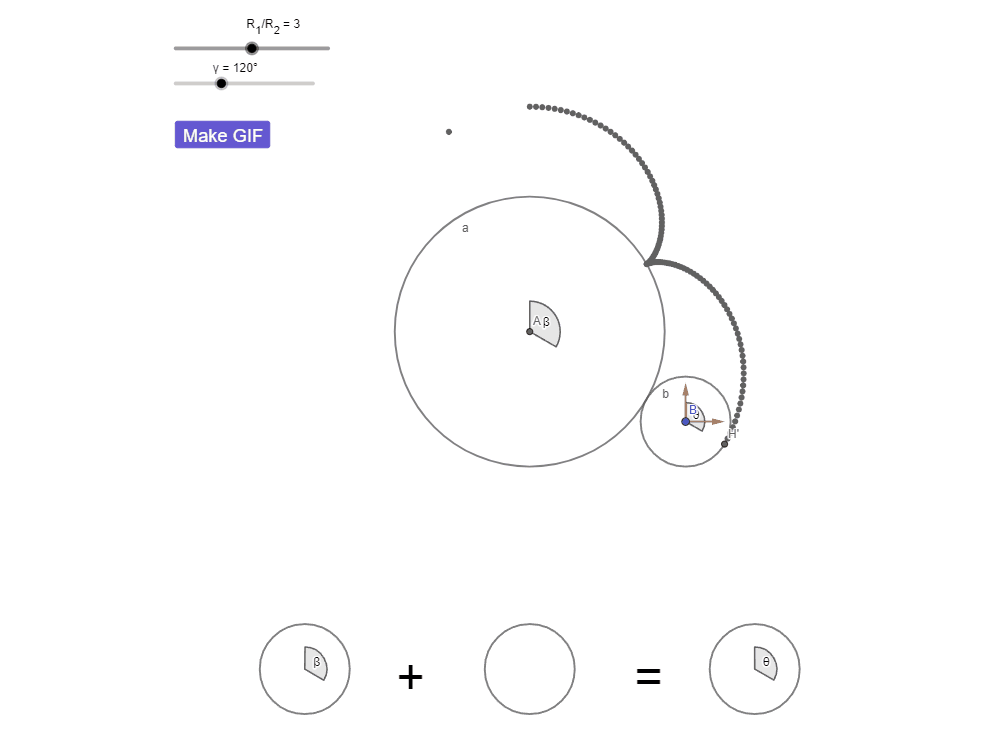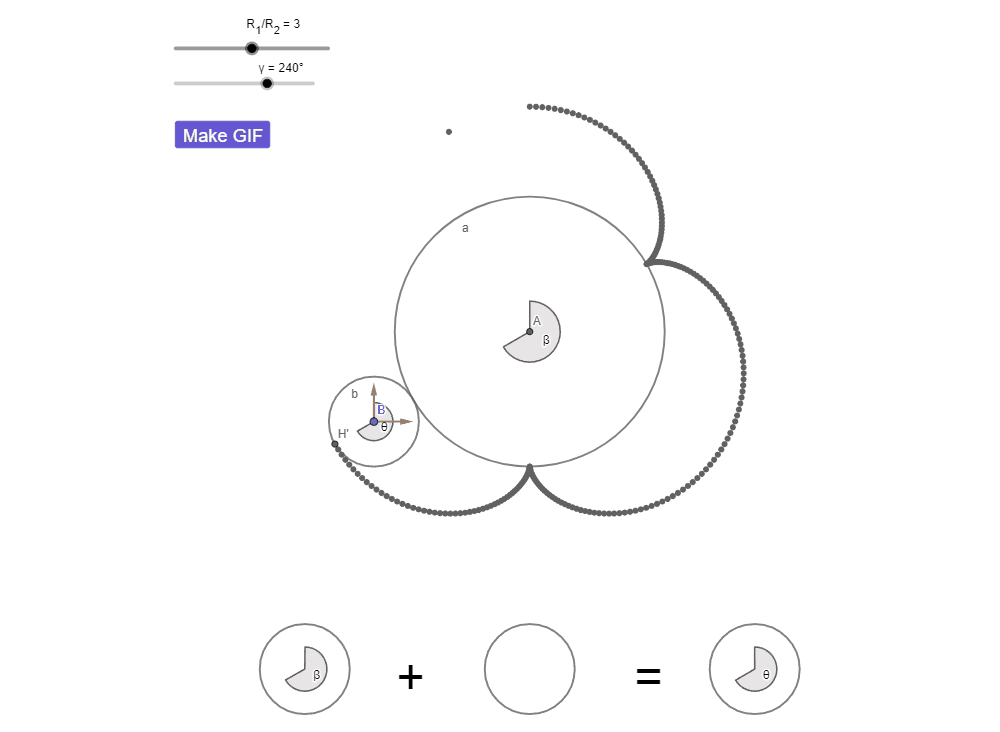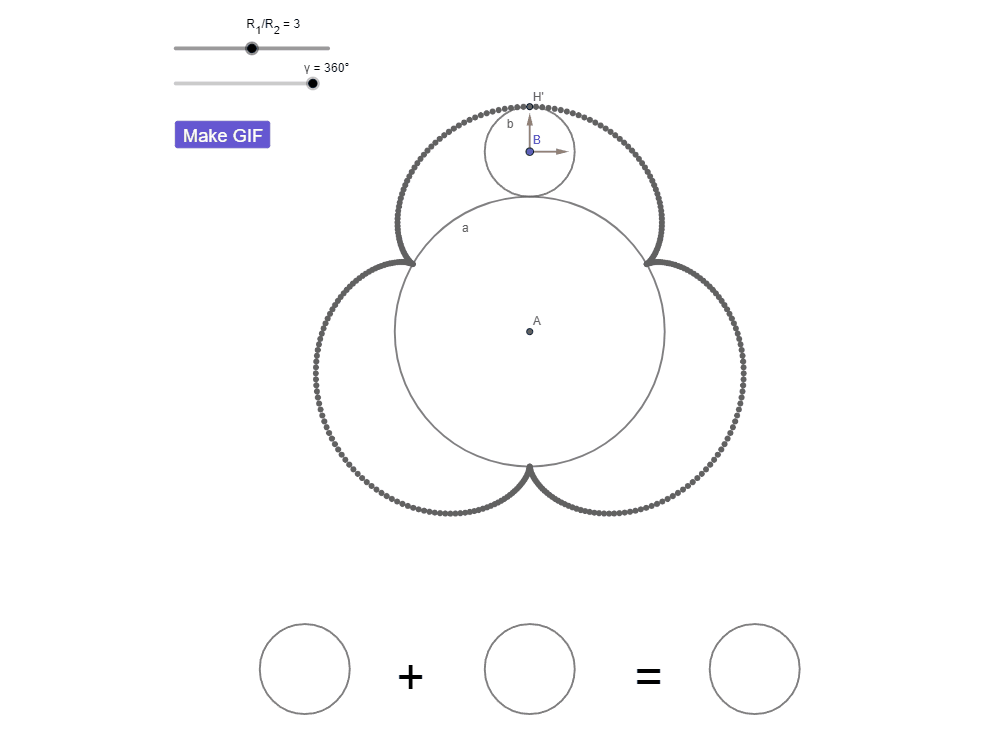
КИ с числами: правильный ответ — 4

КИ с числами: «пропавший» оборот
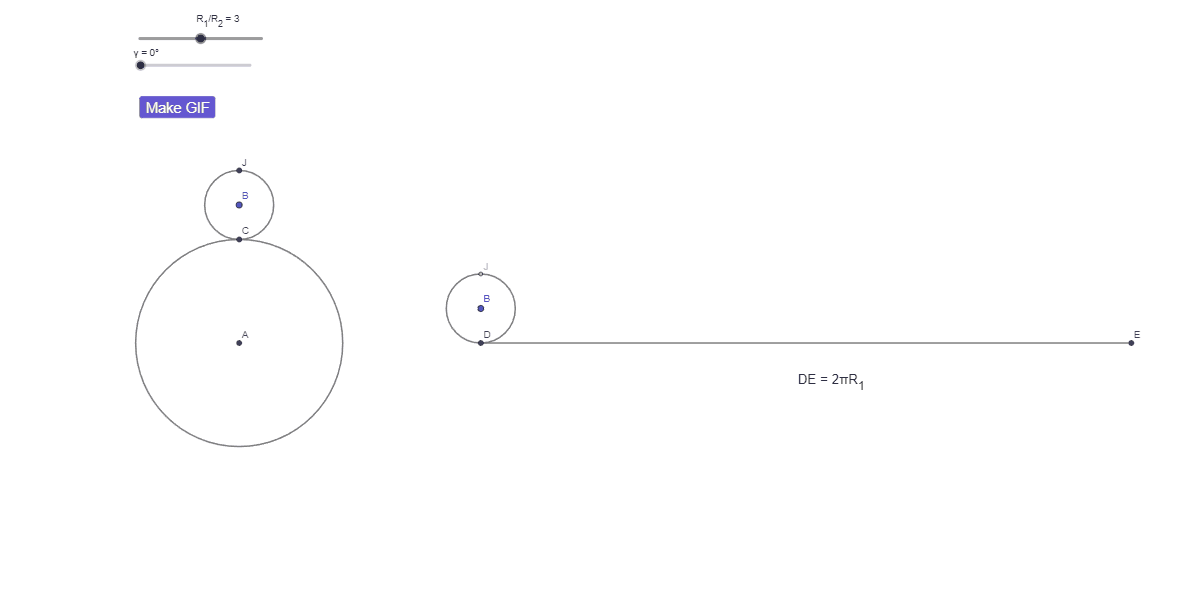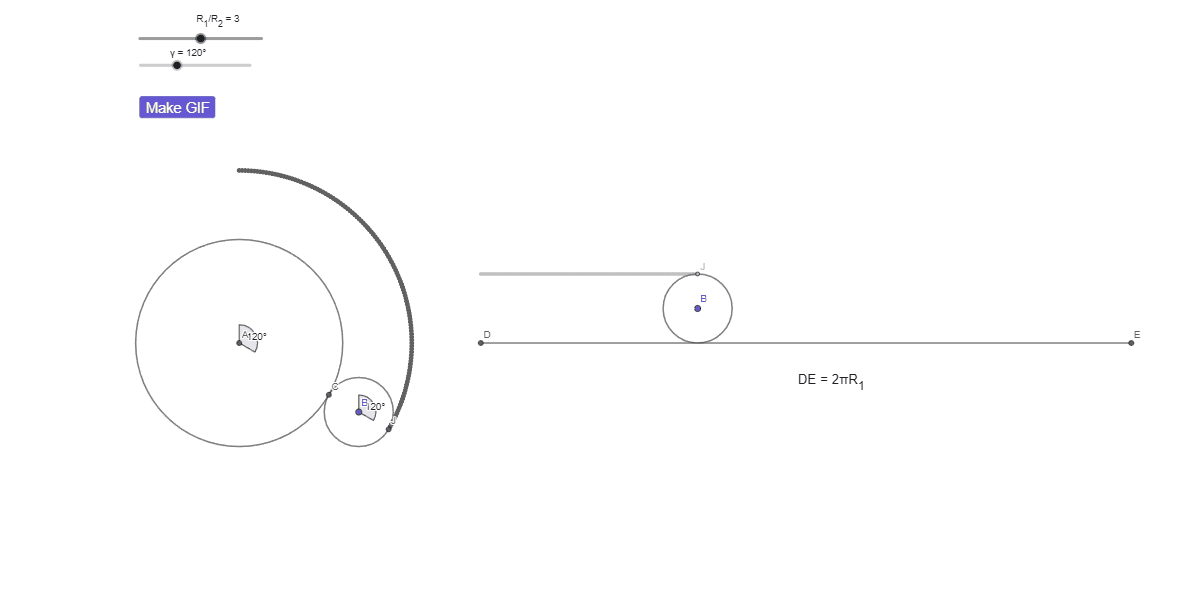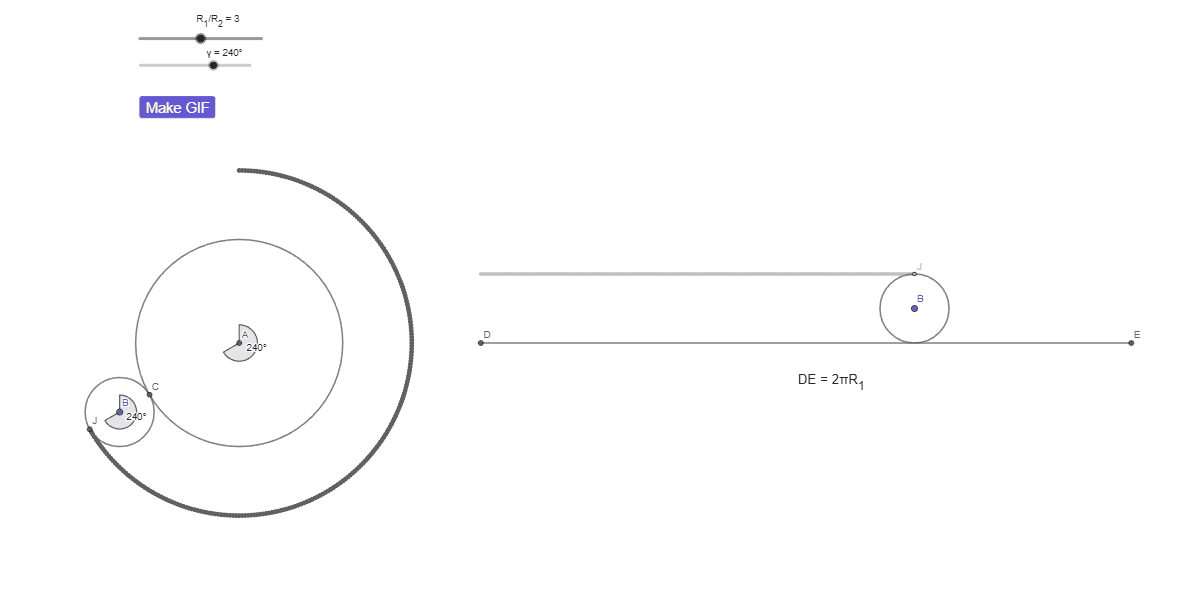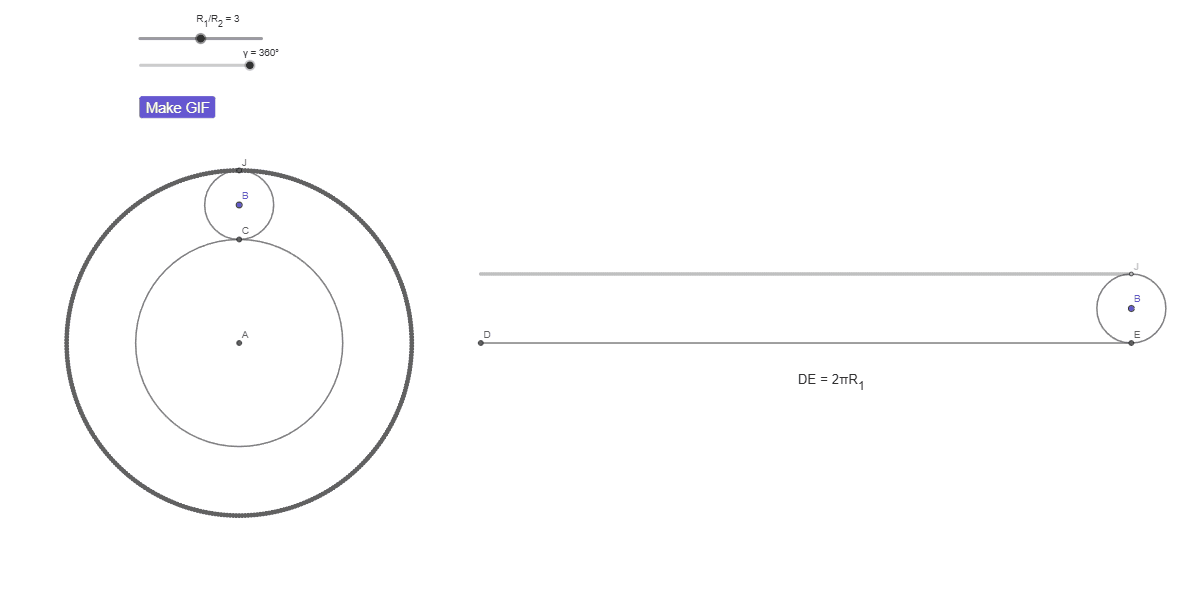
Надеюсь, теперь вы увидели «пропавший» оборот. Достаточно было наблюдать за тем, от чего вас отвлекли — этот дополнительный оборот это оборот окружности b вокруг точки A.
CogBias: Logic & Consistency ≠ Assumptions

КИ с числами: монета не помнит прошлого
Gambler’s Fallacy
H H H H H H H H H → следующий бросок?
Интуиция: «Решка давно не выпадала — пора!»
Реальность: $P(\text{T}) = 0.5$ всегда. Монета не помнит.
Clustering Illusion
Какая последовательность «случайнее»?
H T H T H T H T — выглядит подозрительно
H H H T T H H T — выглядит нормально
Обе одинаково вероятны: $\left(\tfrac{1}{2}\right)^8$
КИ с числами: HH vs HT
Сколько бросков нужно в среднем, чтобы первый раз получить подряд:
| Цель | Интуиция | Реальность |
|---|---|---|
HT (орёл, решка) |
4 | 4 |
HH (орёл, орёл) |
4 | 6 |
Почему HH требует больше бросков?
| После нужного H выпала «не та» монета | Что теряем? | |
|---|---|---|
| HH | H → T → старт с нуля | T бесполезен, предыдущий H потерян |
| HT | H → H → остаёмся в «есть H» | второй H = новый стартовый H |
При цели HT «лишний» H recycleится как новая отправная точка. При цели HH T полностью сбрасывает прогресс.
Структура мишени определяет, насколько «дорого» ошибиться — это не случайность.
КИ профессионалов: задача для врача
Вероятность рака молочной железы у женщин после 40 лет — 1%.
Маммография: чувствительность 80%, ложноположительная ставка 9.6%.
Результат теста — положительный.
Какова вероятность, что у пациентки действительно рак?
Сформулируйте ответ, прежде чем листать дальше.
КИ профессионалов: правильный ответ — 7.8%
Из 1000 женщин:
| Рак (10) | Здорова (990) | |
|---|---|---|
| Тест + | 8 ✓ | 95 ✗ |
| Тест − | 2 | 895 |
Всего положительных: 103
Из них с раком: 8
$$P(\text{рак} \mid +) = \tfrac{8}{103} \approx \mathbf{7.8%}$$
Большинство врачей отвечают: ~80%
Они путают $P(+ \mid \text{рак})$ с $P(\text{рак} \mid +)$.
Это base rate neglect — игнорирование априорной вероятности (1%).
Тест «точный» — не значит что диагноз «точный». Даже хороший тест теряется в море здоровых при редкой болезни.
Парадокс Симпсона: одни данные — разные выводы
Смертность от Covid-27:
| Вакцина Ch27 | Вакцина S27 | |
|---|---|---|
| Лёгкое течение | 210/1400 (15%) | 5/50 (10%) |
| Тяжёлое течение | 30/100 (30%) | 100/500 (20%) |
| Итого | 240/1500 (16%) | 105/550 (19%) |
S27 лучше в каждой подгруппе, но хуже в целом. Как такое возможно?
Парадокс Симпсона: сценарий 1
Состояние C → выбор лечения T → смертность Y
Тяжёлым больным чаще назначают S27 (он дороже и ограничен). Тяжёлое состояние само по себе повышает смертность.
Вывод: нужно смотреть внутри подгрупп → S27 лучше.
Парадокс Симпсона: сценарий 2
Лечение T → состояние C → смертность Y
S27 создаёт очередь → пациенты ждут дольше → болезнь прогрессирует.
Вывод: смотреть в целом → Ch27 лучше.
Парадокс Симпсона — не парадокс, если есть причинная модель.
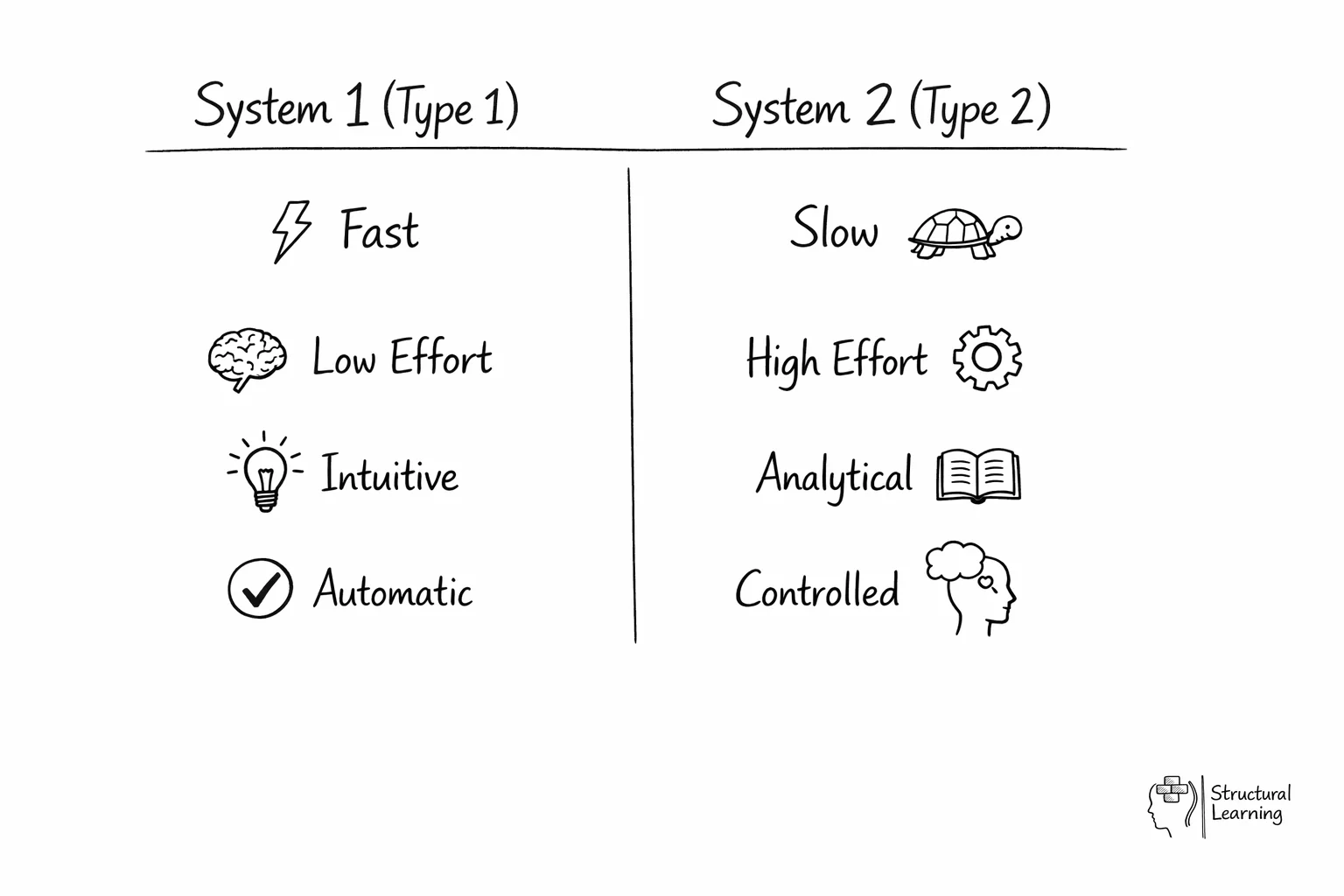
Тип 1 и тип 2
- Вывод типа 1 и расчёт типа 2 конкурируют (типичные задачи на вероятность и логику)
- То, что отрабатывали типом 2, со временем автоматизируется и снова приближается к автономному режиму
- Различать типы надёжнее по автономности и нагрузке на рабочую память, чем только по длительности: тип 1 не всегда «короче по секундам», зато меньше доступен сознательному контролю
| Тип 1 | Тип 2 |
|---|---|
| Автономный запуск | Управляемая последовательность |
| Низкая нагрузка на РП | Высокая нагрузка на РП |
| Эвристики, привычка, модули | Декуплинг, симуляция, нормативы |
| Ответ «по умолчанию» | Может переопределить тип 1 |
Stanovich, K.E. (2011). Rationality and the Reflective Mind. Oxford UP.
When Do We Actually Use Normative Models?
Stanovich, K.E. (2011). Rationality and the Reflective Mind. Oxford UP.
Зачем вообще нужна причинность — даже для прогноза?
Казалось бы: если цель — прогноз, зачем знать механизм?
Рассмотрим данные о курении и смертности:
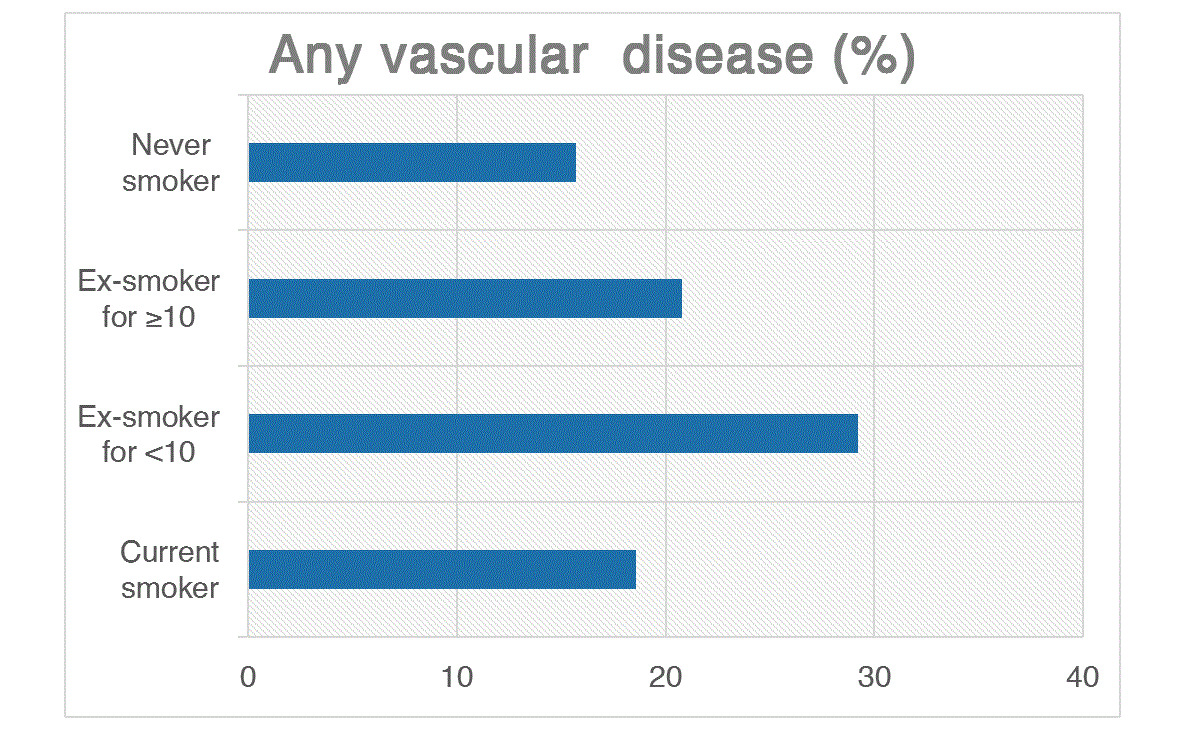
Doll & Hill (1954). Mortality in relation to smoking. BMJ / PMC437139
Что будет, если слепо обучить модель на таких данных?
Четыре проблемы игнорирования причинности
1. Нет объясняющей силы — модель укажет на курение как защитный фактор.
2. Неполная информация — ценные переменные («знает ли пациент о болезни») остаются незамеченными.
3. Нестабильность оценок — перегруппировка данных по времени меняет результаты кардинально.
4. Невозможность трансфера — данные Скандинавии: информирование и курение кажутся равнозначными. Перенос в Бангладеш — модель ломается.
В чём подвох?
Обратная причинность: люди, узнавшие о болезни, бросают курить.
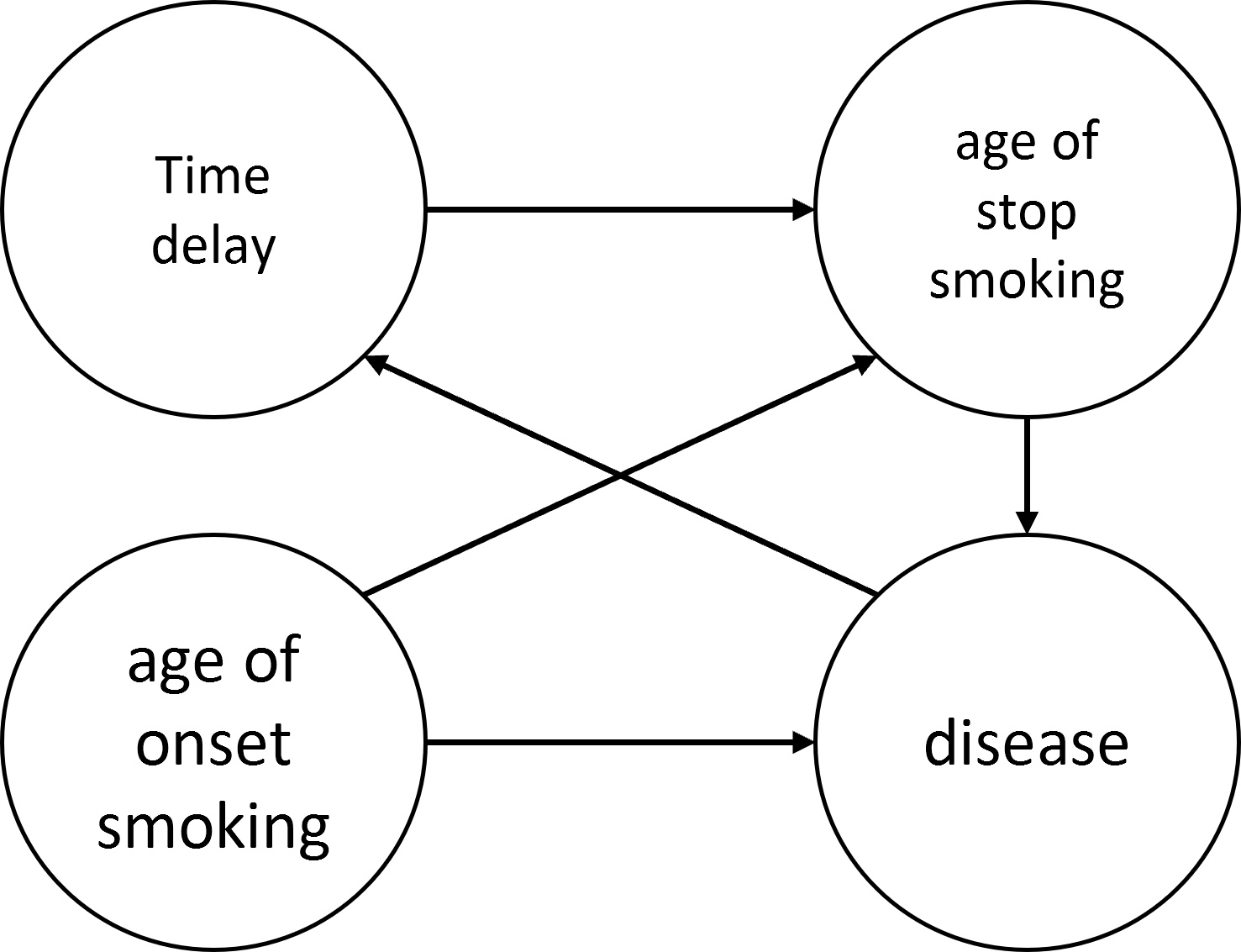
Структура данных, а не сами данные — вот источник ошибки.
Пять расхожих заблуждений о причинности
Мы последовательно разберём каждый из них:
- Корреляция не подразумевает причинность, потому что случайная ассоциация всегда возможна
- Корреляция не подразумевает причинность, потому что данные могут быть неполными
- Отсутствие корреляции означает отсутствие причинности
- Наличие корреляции вообще ничего не означает
- Причинность вообще не выводима из данных
Блок 3 Нормативные модели
Нотация: независимость
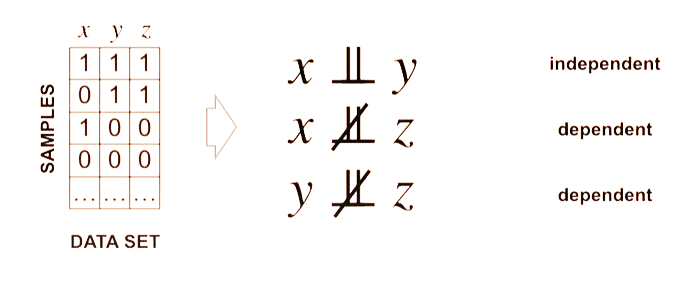
Условная независимость: $X \perp Y \mid Z ;\Leftrightarrow; P(X,Y \mid Z{=}z) = P(X \mid Z{=}z),P(Y \mid Z{=}z) \quad \forall z$
Безусловная независимость: $X \perp Y$ — частный случай ($Z$ пусто).
Пример зависимости: $P(X{=}1)=\tfrac12$, $P(Y{=}1 \mid X{=}1)=0{,}9$, $P(Y{=}1 \mid X{=}0)=0{,}3$ → $X \not\perp Y$.
Интервенция $do(\cdot)$
Наблюдаемое условное $P(Y \mid X{=}x)$ — доля $Y$ среди тех, у кого в данных $X{=}x$ (самовыбор / механизм порождения $X$ сохранён).
Интервенционное $P(Y \mid do(X{=}x))$ — распределение $Y$, если всем принудительно задали $X{=}x$.
Если истинная структура $X \rightarrow Y$ без скрытых общих причин, совпадает: $P(Y \mid X{=}x) = P(Y \mid do(X{=}x))$.
Маргинализация: что это такое
Идея: нас интересует только $X$, но данные содержат ещё и $Y$. Чтобы «убрать» $Y$ — суммируем по всем его значениям:
$$\boxed{P(X) = \sum_{y} P(X, Y{=}y)}$$
Пример: таблица совместного распределения
| $Y{=}0$ | $Y{=}1$ | $P(X)$ | |
|---|---|---|---|
| $X{=}0$ | 0.20 | 0.30 | 0.50 |
| $X{=}1$ | 0.15 | 0.35 | 0.50 |
| $P(Y)$ | 0.35 | 0.65 | 1.0 |
Строка $P(X)$ — сумма по строке. Столбец $P(Y)$ — сумма по столбцу.
Зачем нужно?
- Совместное $P(X,Y,Z,\ldots)$ хранит всю информацию
- Нас интересует только одна переменная → маргинализуем остальные
Связь с законом полной вероятности:
$$P(X) = \sum_y P(X \mid Y{=}y),P(Y{=}y)$$
Маргинализация в DAG: структура
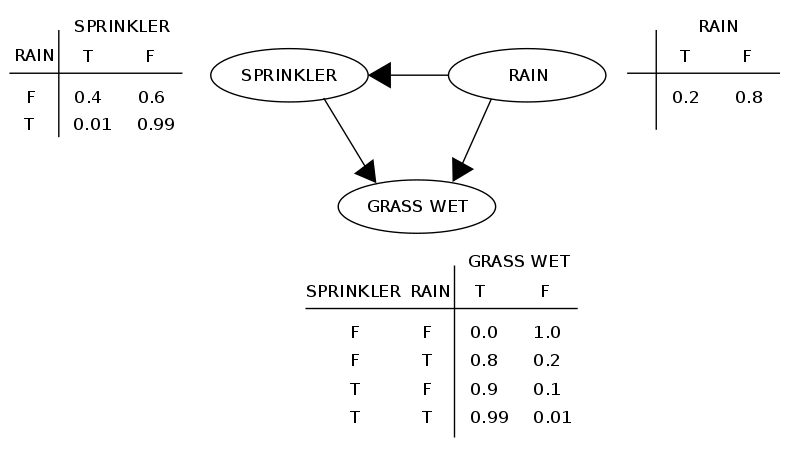
Iuliia Averianova — «Условная независимость — основа байесовской сети»; Koller & Friedman, PGM (2009)
Маргинализация ≠ условие
Маргинализация
не наблюдаем $Z$, суммируем
$$P(X,Y) = \sum_z P(X,Y,Z{=}z)$$
Условие
наблюдаем $Z{=}z$, входим в подвыборку
$$P(X,Y \mid Z{=}z)$$
Эффект противоположный в зависимости от структуры:
| Структура | Маргинализация по $Z$ | Условие на $Z$ |
|---|---|---|
| Коллайдер $X\to Z\leftarrow Y$ | $X \perp Y$ ✓ | $X \not\perp Y$ ✗ (открывает путь) |
| Развилка $X\leftarrow Z\to Y$ | $X \not\perp Y$ (смешение) | $X \perp Y$ ✓ (блокирует) |
Маргинализация — «не смотреть» на $Z$. Условие — «смотреть». В каузальном анализе это принципиально разные операции.
Условная независимость: как интуиция нас обманывает
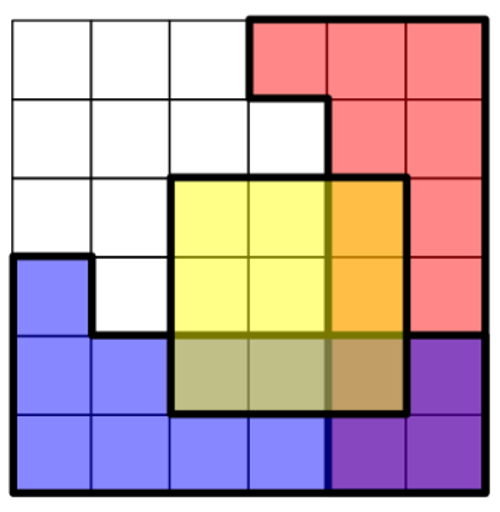
Переменные $Y$ (жёлтая), $R$ (красная), $B$ (синяя).
Вероятность = доля квадратиков в закрашенной области.
$R$ и $B$ зависимы попарно: $P(B \mid R) \neq P(B)$
Но условно независимы при $Y$:
$$P(R \cap B \mid Y) = P(R \mid Y) \cdot P(B \mid Y) = \left(\tfrac{1}{3}\right)^2$$
Добавление $Y$ полностью меняет картину.
Условная независимость: считаем по квадратикам
Всего клеток: 36
Связь R и B (без условия):
$$P® = \tfrac{13}{36}, \quad P(B \mid R) = \tfrac{4}{13} \neq P(B) = \tfrac{11}{36}$$
Зависимы — знание о $R$ меняет вероятность $B$.
Условная независимость при $Y$:
Внутри жёлтой области ($Y$) — 9 клеток.
$$P(R \mid Y) = \tfrac{3}{9} = \tfrac{1}{3}, \quad P(B \mid Y) = \tfrac{3}{9} = \tfrac{1}{3}$$
$$P(R \cap B \mid Y) = \tfrac{1}{9} = \tfrac{1}{3} \cdot \tfrac{1}{3} \checkmark$$
Условие $Y$ «объясняет» связь между $R$ и $B$ — они перестают нести информацию друг о друге.
Принцип Рейхенбаха
Если $A \not\perp B$ — в причинной структуре обязательно есть объяснение
Три базовых варианта:
+ в расширенном графе: медиаторы, коллайдеры, комбинации — но «просто так» зависимость не возникает
Ограничение: по одним наблюдениям принцип не различает эти случаи — они образуют класс наблюдаемой эквивалентности.
Асимметрия причины и следствия
Истинный граф: $A \rightarrow B$
| Ситуация | $A \not\perp B$? |
|---|---|
| Наблюдение | ✓ |
| $do(A)$ — интервенция на причину | ✓ |
| $do(B)$ — интервенция на следствие | ✗ |
Почему так:
$do(B)$ «отрезает» входящие стрелки в $B$ — информации о $A$ в $B$ больше нет.
$do(A)$ оставляет стрелку $A \to B$ нетронутой — связь сохраняется.
$do(\text{следствие})$: связь с причинами — исчезает.
Это делает эксперимент ($do$) главным инструментом проверки направления влияния.
Наблюдаемые эквиваленты: завод
Новый начальник смены хочет проверить связь 4 тумблеров T и 4 линий L.
День 1 — приходит в начале смены:
| T | L |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
Все тумблеры включены, все линии работают.
День 2 — плановое обслуживание:
| T | L |
|---|---|
| 0 | 0 |
| 0 | 0 |
| 0 | 0 |
| 0 | 0 |
Тумблеры выключены, линии не работают.
Что можно заключить?
Три объяснения — одинаково совместимы с данными:
- $T \rightarrow L$
- $L \rightarrow T$
- $(\cdot) \rightarrow T$ и $(\cdot) \rightarrow L$
Наблюдаемые эквиваленты: иллюзия стула

Ситуации AB и AC — наблюдаемые эквиваленты двух разных механизмов. Различить их можно только сравнив ненаблюдаемые состояния.
Различить механизмы: интервенция на T
Физически переключим тумблер: $do(T)$
Case 3: $do(T=1)$
| do(T) | L |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
Case 4: $do(T=0)$
| do(T) | L |
|---|---|
| 0 | 0 |
| 0 | 0 |
| 0 | 0 |
| 0 | 0 |
Если $T \rightarrow L$: линия реагирует → Cases 3 & 4 подтверждают.
Если $L \rightarrow T$: линия не реагирует на переключение тумблера — Cases 3 & 4 будут другими.
Интервенция на причину меняет следствие.
Различить механизмы: интервенция на L
Теперь принудительно меняем линию: $do(L)$
Case 5: $do(L=1)$
| T | do(L) |
|---|---|
| 0 | 1 |
| 0 | 1 |
| 0 | 1 |
| 0 | 1 |
Case 6: $do(L=0)$
| T | do(L) |
|---|---|
| 1 | 0 |
| 1 | 0 |
| 1 | 0 |
| 1 | 0 |
Тумблер не реагирует на интервенцию в линию — значит $T \not\leftarrow L$.
Интервенция на следствие не меняет причину.
Чтобы однозначно исключить все механизмы — нужны минимум две интервенции.
Наблюдаемые эквиваленты: итог

| Механизм | $do(T)$ меняет $L$? | $do(L)$ меняет $T$? |
|---|---|---|
| $T \rightarrow L$ | Да | Нет |
| $L \rightarrow T$ | Нет | Да |
| Общая причина | Нет | Нет |
Разным механизмам соответствует одна проекция в наблюдаемых данных (Cases 1 & 2), но они различаются в контрфактических состояниях (Cases 3–6).
Причинно-следственный механизм — это полный набор всех контрфактических состояний системы.
Оператор $\text{do}()$ и интервенция
Наблюдение: $P(B \mid A=1)$ — смотрим на B, когда видим A=1
Интервенция: $P(B \mid do{A=1})$ — принудительно устанавливаем A=1
Для истинной структуры $A \rightarrow B$:
$$P(B) \neq P(B \mid do{A=1}) \quad \text{(A влияет на B)}$$
$$P(A) = P(A \mid do{B=1}) \quad \text{(B не влияет на A)}$$
Эта асимметрия и отражает причинно-следственную связь.
Контрфактические состояния: от детерминизма к вероятности
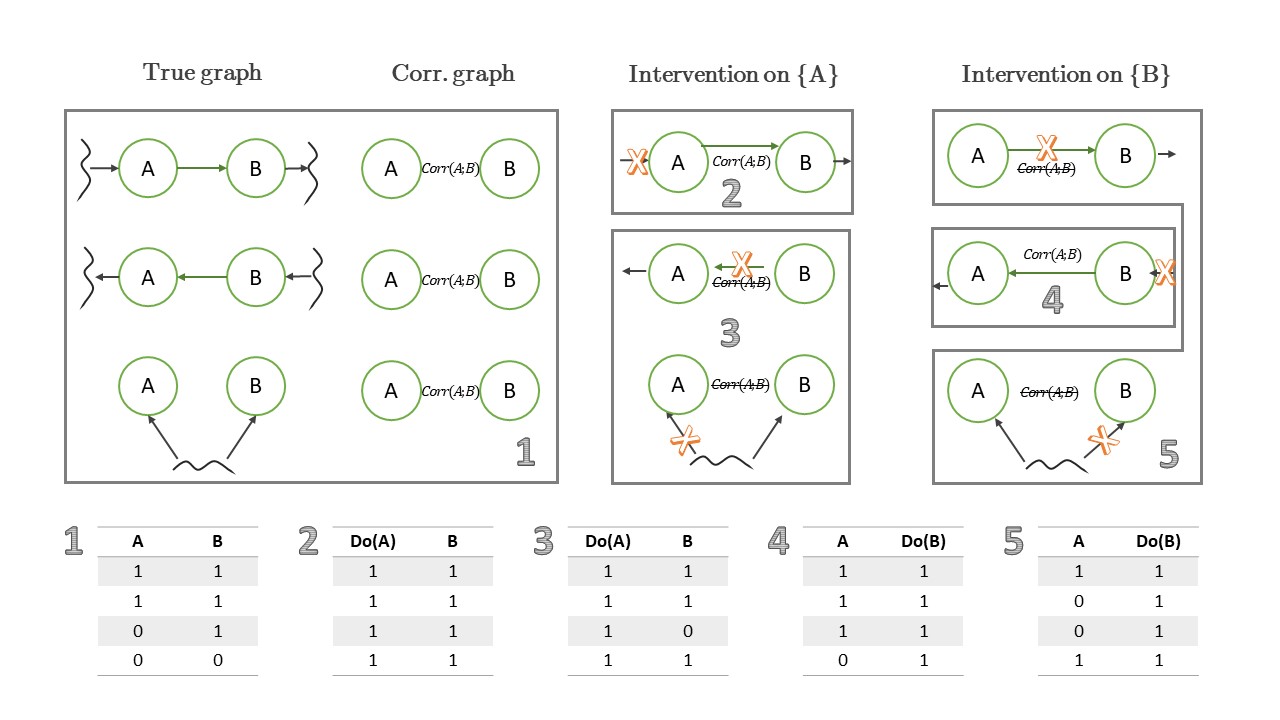
| $P(B \mid do{A})$ | $P(A \mid do{B})$ | |
|---|---|---|
| $A \rightarrow B$ | меняется | не меняется |
| $B \rightarrow A$ | не меняется | меняется |
| Общая причина | не меняется | не меняется |
Нельзя различить все три по одному набору данных — нужны как минимум две интервенции.
Что же всё-таки говорит корреляция?
Три причины скептицизма:
- В высокоразмерных данных ложноположительные связи неизбежны
- Одним данным соответствует несколько механизмов ($X \to Y$ и $Y \to X$ неразличимы)
- Даже зная направление, не знаем функциональную форму ($y=5x$? $y=x^2-5x$?)
Но: это не означает бесполезности корреляции.
Корреляция (ассоциация) сужает класс допустимых причинных структур и в ряде случаев позволяет отбросить целые семейства графов — см. классы наблюдаемой эквивалентности например, коллайдер $X \to Y \leftarrow Z$ (края независимы, оба связаны с $Y$). Зато цепь с $Y$ как единственным посредником между $X$ и $Z$ ($X \to Y \to Z$ или $Z \to Y \to X$) при типичных предположениях (изолированная тройка, faithfulness) с маргинальной $X \perp Z$ несовместима — на концах цепи $X$ и $Z$ были бы зависимы.
$$\text{Graphical Model} ;\leftrightarrow; \text{Independence Set} ;\leftrightarrow; \text{Association Set}$$
$$\downarrow$$
$$\textbf{Identification} ;\longrightarrow; \textbf{Estimator} ;\longrightarrow; \textbf{Estimate}$$
Identification
Какие переменные контролировать? Можем ли мы отделить нужный эффект от остальных?
Ошибка → смещение неустранимо даже при бесконечной выборке.
Estimator
Верная ли функциональная форма? Адекватна ли метрика?
Ошибка → систематическое смещение оценки.
Estimate
Достаточно ли данных, чтобы отличить сигнал от шума?
Ошибка → высокая дисперсия, но смещения нет.
Ошибки идентификации — самые опасные: не исправляются накоплением данных.
Граф и вероятность: три связи
$$\text{Graphical Model} ;\leftrightarrow; \text{Independence Set} ;\leftrightarrow; \text{Association Set}$$
Граф задаёт, кто чей родитель.
Рёбра = разрешённые зависимости.
Отсутствие ребра = запрет прямой связи.
Множество независимостей следует из структуры графа.
$X \perp Y \mid Z$ — если $Z$ d-разделяет $X$ и $Y$.
Статистические ассоциации — наблюдаемые корреляции.
Граф определяет, какие из них возможны, а какие — нет.
DAG делает предположения о зависимостях явными и проверяемыми по данным.
Графические модели: язык для причинности
DAG (Directed Acyclic Graph) — визуализация причинных связей.
$$\text{Графическая модель} \leftrightarrow \text{Множество независимостей} \leftrightarrow \text{Статистические ассоциации}$$
Ключевое свойство — факторизация:
$$P(X_1, \ldots, X_n) = \prod_{i=1}^{n} P(X_i \mid Pa_i)$$
Где $Pa_i$ — родители (причины) узла $X_i$.
DAG делает предположения о причинности явными и проверяемыми.
Граф и вероятность: откуда берётся факторизация
Шаг 1. Условная вероятность:
$$P(A \mid B) = \frac{P(A,B)}{P(B)} ;\Rightarrow; P(A,B) = P(A\mid B),P(B)$$
Шаг 2. Правило цепного умножения (для $n$ переменных):
$$P(q_1,\ldots,q_n) = \prod_{i=1}^{n} P(q_i \mid q_{i-1},\ldots,q_1)$$
Совместное распределение всегда можно расписать через последовательные условные.
Шаг 3. В DAG родители $Pa_i$ — это все прямые причины $X_i$.
По структуре графа $X_i \perp \text{не-потомки} \mid Pa_i$, поэтому длинное условие сокращается:
$$P(q_i \mid q_{i-1},\ldots,q_1) ;\longrightarrow; P(X_i \mid Pa_i)$$
Обобщённая факторизация:
$$P(X_1,\ldots,X_n) = \prod_{i=1}^{n} P(X_i \mid Pa_i)$$
Граф и вероятность: пример
$$P(X_1,\ldots,X_5) = P(X_1);P(X_2\mid X_1);P(X_3);P(X_4\mid X_2,X_3);P(X_5\mid X_3,X_4)$$
$X_1, X_3$ — корни: безусловные вероятности. | $X_5$ не зависит от $X_1, X_2$ напрямую — граф это явно кодирует.
Граф и вероятность: что это даёт
Причинная модель = набор совместных распределений.
Их всегда больше, чем переменных — включают все подмножества с интервенциями:
$$P(X,Y), \quad P(\text{do}(X), Y), \quad P(X, \text{do}(Y)), \ldots$$
Граф при интервенции на причину вложен в наблюдаемый граф.
При интервенции на следствие — нет. Это и есть асимметрия.
Три следствия для практики:
| Что знаем | Что можем |
|---|---|
| Граф | Выписать все допустимые независимости |
| Независимости из данных | Сузить пространство возможных графов |
| Граф + данные | Идентифицировать причинный эффект |
Граф без данных — предположение. Данные без графа — корреляция.
обратная задача, Данные наблюдений: X, Y, Z
| # | X | Y | Z |
|---|
Это те же 16 наблюдений, что в примере с котами ($C, F, G$) — теперь как $X, Y, Z$.
Реальные данные из задачи на интервенции ($X, Y, Z$ — бинарные события).
Попробуйте:
- снять галочки, чтобы отфильтровать строки
- нажать Force Z=1 — это $do(Z{=}1)$: загружается выборка из интервенционного распределения
Данные наблюдений: X, Y, Z
| # | X | Y | Z |
|---|
Это те же 16 наблюдений, что в примере с котами ($C, F, G$) — теперь как $X, Y, Z$.
Попробуйте:
- снять галочки, чтобы отфильтровать строки
- нажать Force Z=1 — это интервенция $do(Z{=}1)$: все значения $Z$ принудительно становятся 1
Частота $Y{=}1$ меняется после $do(Z)$?
Блок 4 структура данных
3×3 таксономия, back-door, bad control
Три базовых структуры: таксономия
Все возможные связи трёх переменных сводятся к двум случаям зависимости:
$$\text{(1)}\quad X_1 \perp X_3 \quad \text{и} \quad X_1 \not\perp X_3 \mid X_2$$
$$\text{(2)}\quad X_1 \perp X_3 \mid X_2 \quad \text{и} \quad X_1 \not\perp X_3$$
| Структура | Случай | Контроль на $X_2$ |
|---|---|---|
| Цепочка $X_1 \to X_2 \to X_3$ | (2) | закрывает путь |
| Развилка $X_1 \leftarrow X_2 \to X_3$ | (2) | закрывает путь |
| Коллайдер $X_1 \to X_2 \leftarrow X_3$ | (1) | открывает путь |
Цепочка: поток через посредника
$$X_1 \longrightarrow X_2 \longrightarrow X_3$$
Без контроля на $X_2$:
$X_1 \not\perp X_3$ — коррелируют.
Информация «течёт» по цепочке.
При контроле на $X_2$:
$X_1 \perp X_3 \mid X_2$ — независимы.
Посредник «перекрыт» — поток разорван.
Пример: рост → вес → давление. Убрав из анализа вес, рост и давление снова «связаны».
Развилка: общая причина (конфаундер)
$$X_1 \longleftarrow X_2 \longrightarrow X_3$$
Без контроля на $X_2$:
$X_1 \not\perp X_3$ — коррелируют.
Общая причина создаёт ложную связь.
При контроле на $X_2$:
$X_1 \perp X_3 \mid X_2$ — независимы.
Конфаундер «нейтрализован».
Пример: праздничный сезон → открытки И → украшения. Убрав сезон — связь исчезает.
Коллайдер: обратная логика
$$X_1 \longrightarrow X_2 \longleftarrow X_3$$
Без контроля на $X_2$:
$X_1 \perp X_3$ — не коррелируют.
Путь по умолчанию закрыт.
При контроле на $X_2$:
$X_1 \not\perp X_3 \mid X_2$ — начинают коррелировать!
Контроль открывает ложный путь.
Единственная структура, где контроль вредит — добавление коллайдера в регрессию порождает ложную связь.
Коллайдер: числовой пример (парадокс Берксона)
$A$ и $B$ — независимые причины. $AB$ — их общее следствие (коллайдер).
Ряд $A$: 0 1 0 1 0 1 0 1
Ряд $B$: 0 0 1 1 0 0 1 1
$A$ и $B$ независимы по построению.
$AB$: 0 0 0 1 0 0 0 1 1 1 0 1 1 1 0 1
| $A$ | $\neg A$ | |
|---|---|---|
| $B$ | $A \cap B = 1$ | $\neg A \cap B = 0$ |
| $\neg B$ | $A \cap \neg B = 0$ | $\neg A \cap \neg B = 0$ |
При отборе только $AB=1$:
пары ${1,1}$ и ${1,1}$ — сильная положит. корреляция
Отбор по следствию автоматически создаёт корреляцию между независимыми причинами.
Три базовые структуры: recap
\(X_1 \to X_2 \to X_3\)
| безусловно | \(X_1 \not\perp X_3\) |
| \(\mid X_2\) | \(X_1 \perp X_3\) |
\(X_1 \leftarrow X_2 \to X_3\)
| безусловно | \(X_1 \not\perp X_3\) |
| \(\mid X_2\) | \(X_1 \perp X_3\) |
\(X_1 \to X_2 \leftarrow X_3\)
| безусловно | \(X_1 \perp X_3\) |
| \(\mid X_2\) | \(X_1 \not\perp X_3\) |
25 возможных графов на трёх переменных
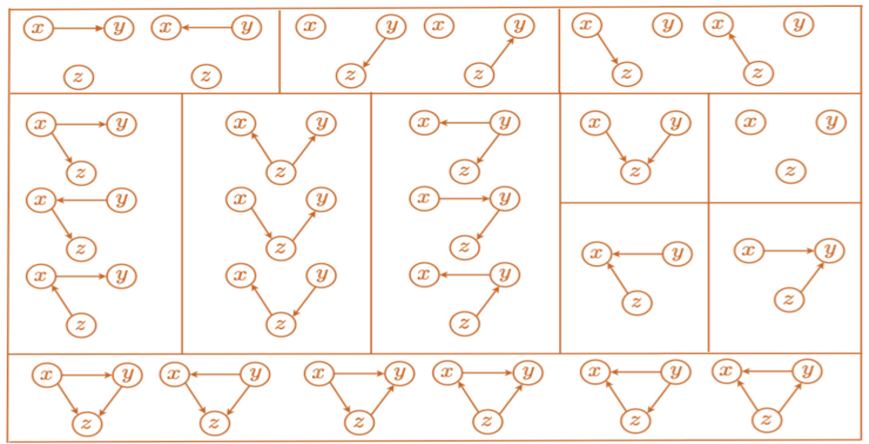
Ровно 25 сценариев для трёх изолированных переменных. Графы в одном прямоугольнике — неразличимы по наблюдаемым данным. Коллайдеры и независимые пары идентифицируемы всегда. Остальное — нужны предположения или эксперименты.
Back-door критерий: от структуры к оценке
Проблема: знания о структуре недостаточно для численной оценки эффекта.
Нужно выбрать — что включать в контроль:
| Тип контроля | Пример | Эффект |
|---|---|---|
| Хороший (конфаундер) | $Z \rightarrow X$, $Z \rightarrow Y$ | Блокирует ложную связь ✓ |
| Плохой (медиатор) | $X \rightarrow M \rightarrow Y$ | Блокирует причинный путь ✗ |
| Нейтральный | $Z \rightarrow X \rightarrow Y$ | Не нужен, не вредит |
Back-door критерий: формулировка
$Z$ удовлетворяет back-door критерию для $(X, Y)$, если:
- Ни одна переменная из $Z$ не является потомком $X$
- $Z$ блокирует все пути со стрелкой, входящей в $X$
| Паттерн | Контроль на $B$ |
|---|---|
| Цепочка $A \to B \to C$ | блокирует ✓ |
| Развилка $A \leftarrow B \to C$ | блокирует ✓ |
| Коллайдер $A \to B \leftarrow C$ | открывает ✗ |
Back-door выполнен → линейная регрессия по скорректированным данным даёт причинный эффект.
Хороший и плохой контроль: обзор
✓ Хороший контроль
Блокирует ложные (backdoor) пути, не трогая причинный.
Конфаундер $Z$: $Z\to X$, $Z\to Y$. Контроль убирает смешение.
✗ Плохой контроль: медиатор
Блокирует сам причинный путь.
$X\to M\to Y$: контроль $M$ занижает или обнуляет $P(Y\mid do(X))$.
✗ Плохой контроль: коллайдер
Открывает ложный путь между $X$ и $Y$.
$X\to C\leftarrow Y$: $X\perp Y$ без контроля, но $X\not\perp Y\mid C$ — ложная связь.
Cinelli, C., Forney, A., Pearl, J. A Crash Course in Good and Bad Controls (2022)
Плохой контроль: M-bias и потомок исхода
✗ M-bias (бабочка)
$C$ не конфаундер — но контроль открывает ложный путь.
$A\to X$, $A\to C\leftarrow B$, $B\to Y$. $X$ и $Y$ независимы — контроль $C$ создаёт смешение через $A$ и $B$.
✗ Потомок исхода
Контроль $D$ (потомка $Y$) создаёт обратный поток.
$Y\to D$: контроль $D$ частично обусловливает $Y$ → смещает оценку $X\to Y$.
Практическое правило
| Тип | Контролировать? |
|---|---|
| Конфаундер $Z\to X$, $Z\to Y$ | ✓ Да |
| Медиатор $X\to M\to Y$ | ✗ Нет |
| Коллайдер $X\to C\leftarrow Y$ | ✗ Нет |
| Потомок коллайдера | ✗ Нет |
| M-bias узел $C$ | ✗ Нет |
| Потомок $Y$ | ✗ Нет |
| Инструментальная переменная | ○ Зависит |
Cinelli, C., Forney, A., Pearl, J. A Crash Course in Good and Bad Controls (2022)
Блок 5 — Recap
Фундаментальная проблема причинно-следственного вывода
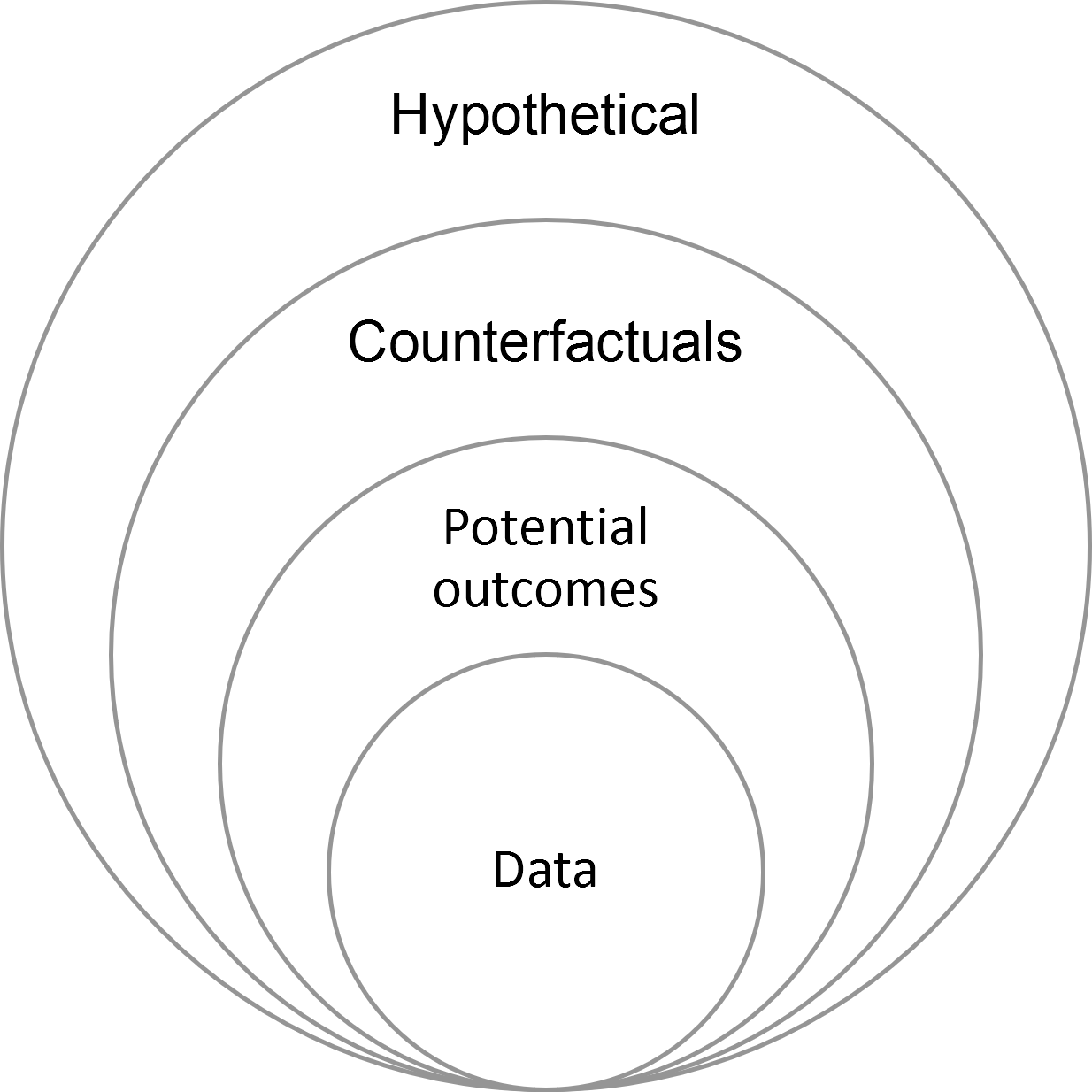
Мы не можем одновременно наблюдать все альтернативные состояния.
$$Y_i(1) - Y_i(0) \text{ — ненаблюдаем напрямую}$$
Нужны предположения:
- Интервенции независимы друг от друга
- Идентичные объекты реагируют одинаково (SUTVA)
- Нет скрытых общих причин
Стратегии идентификации: обзор
Эксперименты
рандомизация устраняет конфаундинг
- RCT, естественные эксперименты
- Ортогональный дизайн
- Факторный дизайн
- Discovery + интервенции
- Адаптивные: бандиты, sequential testing, sample-efficient
Matching
контрфактуал из наблюдений
- Propensity score / IPW
- Matching (NN, exact…)
- Synthetic control
- Diff-in-differences (DiD)
- Instrumental variables (IV)
- Regression discontinuity
Структурные
ограничиваем класс моделей
- LiNGAM
- SEM / econometrics
- Additive noise (ANM)
Частичная
bounds вместо точки
- Causal Discovery
- Bound estimation
- Sensitivity analysis
- «Не знаем» — тоже ответ
› Выбор стратегии — это дизайн исследования и допустимые предположения, а не объём данных.
Иерархия ошибок: три уровня
| Уровень | Что нарушено | Пример ошибки |
|---|---|---|
| Верхняя онтология | правила причинного вывода | включили коллайдер в регрессию |
| Средняя онтология | модель конкретного механизма | предположили аддитивность там, где её нет |
| Нижняя онтология | качество измерений | повторных покупателей посчитали новыми |
Верхняя онтология — логическая ошибка: не зависит от данных и не исправляется их накоплением.
Средняя — ошибка контекста: неверно выбран гипотетический механизм.
Нижняя — ошибка данных: можно исправить протоколом сбора.
Типичные ошибки причинного мышления
Reverse causation
Путаем направление: $B$ вызывает $A$, а мы думаем что $A\to B$.
Пример: низкий холестерин → смерть? Нет — болезнь снижает холестерин и убивает.
Mediation confusion
Контролируем медиатор $M$ на пути $X\to M\to Y$ и «теряем» эффект.
Пример: контроль на зарплату при изучении влияния образования на доход.
Collider / selection bias
Выборка через коллайдер создаёт ложную отрицательную корреляцию.
Пример: в больнице диабет и холецистит выглядят связанными — хотя независимы в популяции.
Proportionality bias
«Большое событие — большая причина». Малые причины больших событий кажутся неправдоподобными.
Пример: смерть принцессы Дианы → теория заговора вместо случайной аварии.
Regression fallacy
Регрессия к среднему принимается за эффект вмешательства.
Пример: боль уменьшилась после врача — но она и так должна была уменьшиться.
Single cause fallacy
Ищем одну причину там, где их несколько и они совместно достаточны.
Пример: «COVID вызвала вакцина» — игнорируя все остальные факторы.
Все шесть ошибок — следствие игнорирования структуры.
Таксономия ошибок причинного вывода
- Слабая идентификация
- Опущенные переменные
- (1) Confounding
- (2) Обратная причинность
- (3) Lord's paradox
- (4) Collider / Berkson
- (5) Proximate vs ultimate
- (6) Simpson's paradox
- (9) Телеология
- (14) Proportionality bias
- (15) Single cause fallacy
- (16) Regression fallacy
- (7) Post hoc ergo propter hoc
- (8) Survivorship bias
- (10) Hawthorne effect
- (11) Ecological fallacy
- (12) Gambler's fallacy
- (13) Texas sharpshooter
- (17) Outcome bias
- (19) Unit heterogeneity
- (21) Рандомизация кластеров
- (22) Non-random assignment
- (23) Perfect oracle assumption
- Path neglect bias
- Selection bias
- Assignment violation
- Exchangeability violation
- SUTVA violation
- (20) Mediation / moderation
- (24) Fat tails
- (25) Small samples
- (26) Interference
- (27) Noncompliance / attrition
- (28) Misreport / contamination
- (29) Network effect
- (30) Spillover
- Narrative bias
- Protocol violation
- (18) Recession shapes
- (31) Multiple comparisons
- (32) Overcontrol bias
- (33) Level of measurement
- (34) Model misspecification
- (35) Data dredging
- (36) NHST misinterpretation
- (37) HARKing / preregistration
- Bad standards & incentives
Что данные могут сказать сами: PC-алгоритм
Алгоритм Peter-Clark восстанавливает структуру DAG только из наблюдений — без экспериментов.
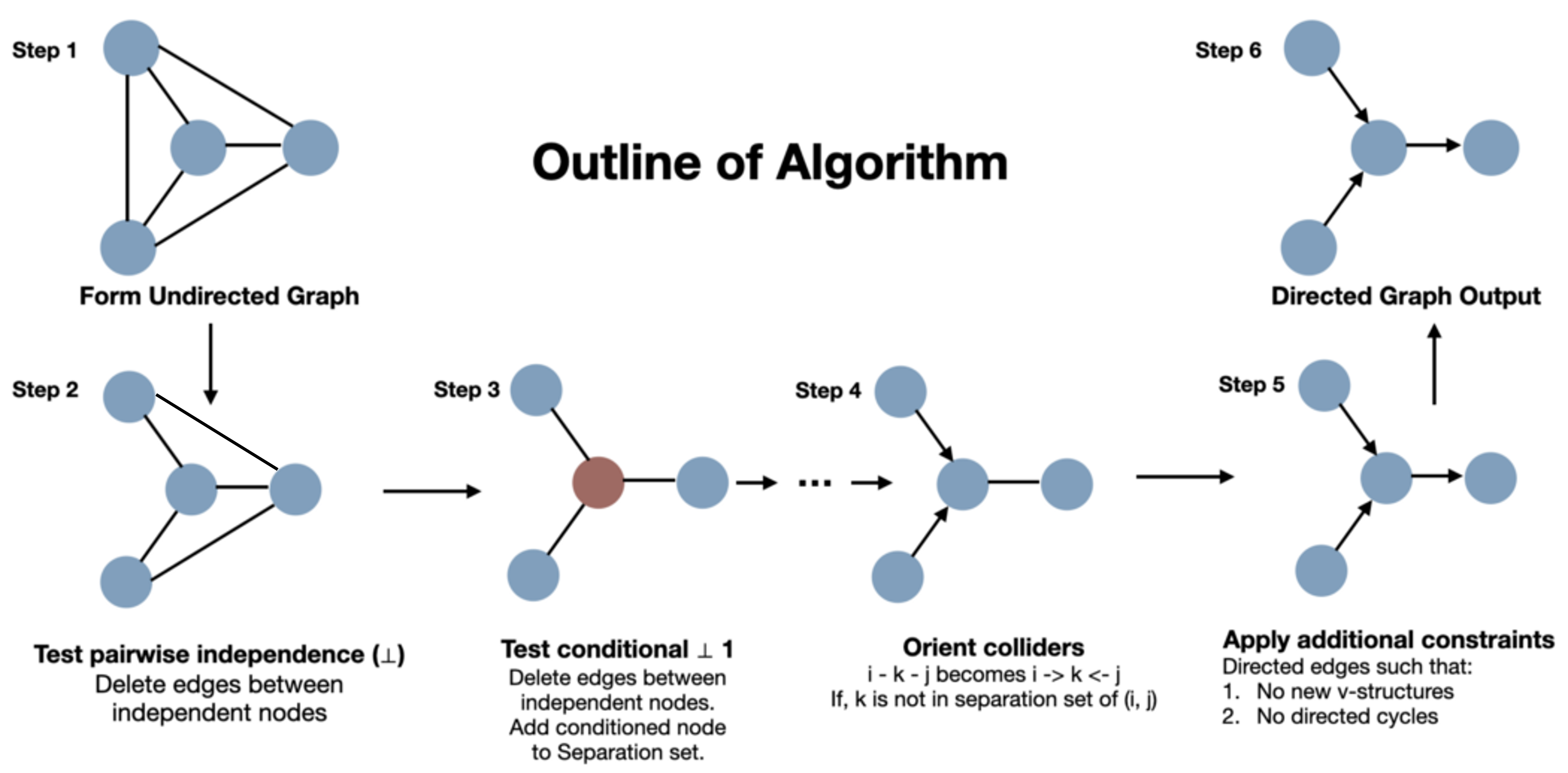
PC-алгоритм: шаги
| Шаг | Действие |
|---|---|
| 1 | Полный граф — соединить все переменные |
| 2 | Попарная независимость — удалить рёбра между независимыми парами |
| 3 | Условная независимость — удалить рёбра, если $X \perp Y \mid Z$ |
| 4 | Ориентировать коллайдеры: если $X - Z - Y$ и $Z \notin Sep(X,Y)$, то $X \to Z \leftarrow Y$ |
| 5 | Ограничения: нет новых коллайдеров, нет циклов |
| 6 | Результат: частично ориентированный граф |
Данные сужают пространство возможных механизмов даже без экспериментов.
Что подразумевает причинность: контрфактические состояния, оператор $do()$, предположения о структуре, интервенции как наиболее надёжный источник свидетельств
Что говорит корреляция: исключает механизмы, идентифицирует коллайдеры и независимости, при минимальных предположениях восстанавливает структуру
Нормативные фреймворки: Наблюдаемый эквивалент, условная независимость, ассиметрия и контрфактические состояния
When Do We Actually Use Normative Models?
Stanovich, K.E. (2011). Rationality and the Reflective Mind. Oxford UP.
Рекап: нормативные фреймворки
Разные причинные структуры → одно наблюдаемое распределение. Различить можно только через контрфактические состояния или интервенции.
$Pa_i$ — прямые причины. Совместное распределение: $P(X_1,\ldots,X_n)=\prod P(X_i \mid Pa_i)$.
Граф кодирует структуру независимостей — не числа, а топологию.
Граф → набор условных независимостей → допустимые ассоциации. Изменение любого звена меняет всю цепь.
Сначала — условие идентификации (back-door / front-door). Затем — метод. Только потом — число.
Цепочка $X_1\to X_2\to X_3$: $X_1\not\perp X_3$, но $X_1\perp X_3\mid X_2$.
Развилка $X_1\leftarrow X_2\to X_3$: то же independence set — неразличимы по наблюдениям.
Коллайдер $X_1\to X_2\leftarrow X_3$: $X_1\perp X_3$, но $X_1\not\perp X_3\mid X_2$ — уникален, идентифицируем.
$do(\text{причина})$: зависимости среди следствий сохраняются.
$do(\text{следствие})$: связь с причиной исчезает.
Граф следствий после $do(\text{причина})$ = наблюдаемому графу — не наоборот.
Наблюдаемый граф ($I{=}\emptyset$) вложен в интервенционный граф ($I{=}\{X\}$) при интервенции на причину.
При интервенции на следствие — вложенности нет. Это делает эксперимент принципиально информативнее наблюдения.
Источники

Книги и курсы
- Pearl, J. The Book of Why (2018)
- Cunningham, S. Causal Inference: The Mixtape — онлайн
- Neal, B. Introduction to Causal Inference (2020) — курс
- Koller, D. & Friedman, N. Probabilistic Graphical Models (2009)
- Peters, J., Janzing, D., Schölkopf, B. Elements of Causal Inference (2017)
- Spirtes, P. et al. Causation, Prediction, and Search (2000)
- Montgomery, D. / Box, G. & Hunter, J. — классические учебники по DOE
Иллюстрации и блоги
- Talebi, S. Causal Discovery: Learning causation from data — иллюстрации PC
- Averianova, I. / Kim, A. Условная независимость — основа байесовской сети — маргинализация и условная независимость
Статьи
- Cinelli, C., Forney, A., Pearl, J. A Crash Course in Good and Bad Controls (2022)
- Eberhardt, F., Glymour, C., Scheines, R. On the number of experiments… (2012)
- Eberhardt, F. Introduction to the Foundations of Causal Discovery (2017)
- Glymour, C., Zhang, K., Spirtes, P. Review of Causal Discovery Methods (2019)
- Vowels, M. J. et al. D’ya Like DAGs? A Survey on Structure Learning (2022)
- Heinze-Deml, C., Maathuis, M. H., Meinshausen, N. Causal Structure Learning (2018)
- Nogueira, A. R. et al. Causal Discovery in Machine Learning (2022)
- Hitchcock, C. & Rédei, M. Reichenbach’s Common Cause Principle (2020)
- Sabbaghi, A. & Rubin, D. B. Comments on the Neyman–Fisher Controversy
- Eberhardt, F. Causality: From Aristotle to Zebrafish (2019)
Спасибо
Вопросы?
«Если отбросить всё невозможное, то то, что останется, каким бы невероятным оно ни казалось, и будет истиной.»